Den här artikeln publicerades ursprungligen på SightSize.com och är översatt från engelska. "Sight-size" är en traditionell metod för realistiskt måleri.
Den här artikeln råkar vara nummer två i en serie om modellering. Läs del 1 och del 3 här.
De flesta konstnärer som tränats i sight-size använder metoden valör framför form när de modellerar. Att modellera på detta sätt hjälper konstnären att bibehålla helhetssynen (vilket representerar bilden som en hel ensemble), liksom den sammanhållna effekten. Denna metod minskar naturligt risken att falla in i detaljseende.
Som vi minns från den förra artikeln så baseras form framför valör-metoden på en förståelse av hur ljuset färdas när det träffar en form och sedan reflekteras tillbaka till betraktarens öga. Därför modellerar man vanligen med en remsa, en sektion eller muskel. Målet i detta fall, och om vi var tvungna att reducera det till bara ett, är att representera illusionen av den tredimensionella formen på en tvådimensionell yta.

Bilderna ovan visar modellritning av tre elever vid Madrid’s Real Academia de Bellas Artes de San Fernando. De är från 1902, tecknades vid samma tillfälle, och är av samma modell. Var och en av dem representerar valör framför form-modellering.
Omvänt förlitar sig valör framför form-metoden helt och hållet på konstnärens förmåga att korrekt uppfatta relationerna mellan iakttagna former och valörer så som de faktiskt ses på objektet. När dessa iakttagelser representeras uppstår det ofta en skillnad mellan vad objektet bokstavligen är, och de abstrakta formerna och valörerna som i kombination låter oss känna igen det. Den här konstnärens mål är att representera sin vision av objektet som han eller hon såg det visuellt.
Så, hur gör man egentligen?
Den grundläggande metoden att modellera med valör framför form är att relatera varje iakttagen valör i scenen till alla andra iakttagna valörer i scenen. Dessa relationer representeras sedan i ditt konstverk, i vilken som helst relativ tonskala som ditt medium klarar av. Efter att ha etablerat arabesken (konturen) och skugglinjen börjar du gruppera de observerade ytterligheterna: det mörkaste mörka och det ljusaste ljusa.
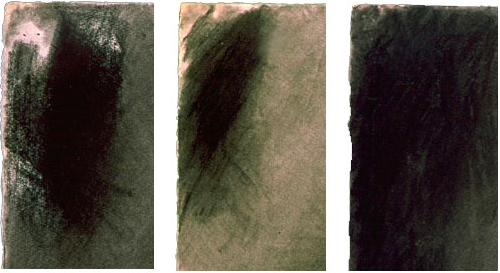
Lägg märke till, i den figurativa teckningens detaljer ovan, att var och en har ett väldigt mörkt område som anges i bakgrunden uppe till vänster. Dessa var, vad jag tror, det mörkaste mörka i scenen, som var och en av konstnärerna noterade. Antagligen var det de djupt skuggiga områdena i rummet bakom modellen. Vit krita tjänade som det ljusaste ljusa, som visar sig i teckningarnas högdagrar. Lägg också märke till att eleverna jobbade på tonat papper som lämnades orört på vissa ytor.

Modellteckning av Herminio Novella Roldán (1902)
Ovan är den mittersta teckningen av de tre exemplen. Jag valde att fokusera på den eftersom den är inte är färdig. Tack vare att den är ofärdig visar oss nedre delen av benen, från knäna och nedåt, och modellens högra arm, hur Roldán gick till väga när han modellerade denna gestalt.
Som sagt, när arabesken hade etablerats märktes skugglinjen noggrant ut. Denna syns fortfarande tydligt på modellens vänstra skenben och fotled. De skuggade ytorna verkar ha lagts in i hela bilden.
Därpå indikerades många av de mörkare halvtonerna, och några av högdagrarna antyddes.
Efter det mjukades de angivna valör-områdena upp, kanterna buktades och accenterna stärktes.*
Genom hela modelleringsprocessen jämförde Roldén kontinuerligt valören han var ute efter med de observerade valör-ytterligheterna. Med dessa jämförelser relaterades alla valörer till scenens helhet.
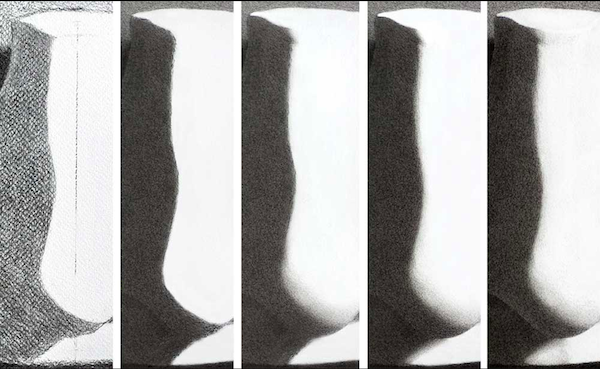
Bilden ovan visar en serie med detaljer av en antikritning som modellerades med hjälp av valör framför form-metoden. På grund av beskärningen är bilden lite missvisande. Jag kunde inte presentera en bildrad av hela ritningen på skärmen på en och samma gång. Inte desto mindre, när teckningen skapades relaterades alla valörer och kanter till hela scenen.
Stegen som användes för att skapa teckningen var som följer (från vänster till höger):
Bild 1: Gipsavgjutningens arabesk, skugglinje och linjen kring kastskuggan bestämdes. Jag kisade när jag hittade och lade in det mörkaste mörka (vilket var kastskuggan), det näst ljusaste mörka (skuggan på gipsavgjutningen) och bakgrunden. Papprets valör var det ljusaste ljusa.
Bild 2: Sedan stärkte och mjukade jag upp de tre valörerna.
Bild 3: Medan jag tittade på hela scenen utsåg jag det skarpaste skarpa och det mjukaste mjuka på skugglinjen.
Bild 5: Slutligen lade jag till halvtonerna (vilka anses vara i världen av ljus), och det reflekterade ljusen (vilka är i världen av skugga), som alla ses relaterade till de ovan nämnda valör-ytterligheterna.
* Den skarpögda kommer att lägga märke till att Roldán använder en typ av "rullgardinsmetod" – att han tecknar uppifrån och ned. Ja, man kan modellera valör framför form och fortfarande teckna uppifrån och ned. Men vid en närmare titt kommer du även se att den initiala grupperingen och modelleringen gjordes genomgående i hela teckningen. Bara efter detta började han tighta till saker uppifrån och ned. Eftersom det är omöjligt att bokstavligen jobba överallt samtidigt gjorde Roldán det nödvändiga valet.
Denna artikel är ett utdrag ur min bok The Sight-Size Cast.
Darren R Rousar är en ateljé-utbildad konstnär och lärare som skriver böcker som lär människor hur man tecknar och målar. Han gör detta genom att först lära dem att se. Hans senaste bok är ”The Sight-Size Cast”. Varannan vecka publicerar han artiklar på SightSize.com